
I am currently a third-year Master’s student at the School of Computer and Software, Shenzhen University, supervised by Prof. Fei Richard Yu. I am also fortunate to be advised by Prof. Yao Shu.
My research interests primarily lie in the post-training of Large Language Models (LLMs), including Supervised Fine-Tuning (SFT), Prompt Optimization, and Reinforcement Learning (RL). Additionally, I am interested in learning theories, such as Machine Learning Theory, Optimization Theory, Reinforcement Learning Theory.
If you are interested in my research, please feel free to contact me via .
🔥 News
- 2025.12: 🎉🎉 ReDit is accepted by NeurIPS 2025.
- 2025.11: 🎉🎉 UniSVG is accepted by ACM MM 2025 Dataset Track.
- 2025.11: 🎉🎉 PAFT is accepted by EMNLP 2025, and wins the SAC Highlights Award (TOP 2%) at EMNLP 2025!
- 2025.10: I serve as a reviewer for ICLR 2026.
- 2025.10: We propose GAPO, a method that robustly handles skewed reward distributions with outliers in code-editing RL by adaptively computing advantages, leading to consistent performance improvements. Check our Github.
- 2025.10: We propose R-Score, a novel metric to quantify the learnability of queries in RL to enhenced the curriculum learning method. Check our Github.
- 2025.09: We propose ROSA, a lightweight algorithm for our test-time adaptation paradigm that enables LLMs to perform efficient in-conversation self-correction by updating parameters online using real-time user feedback. Check our Github.
- 2025.08: We propose UniSVG, a SVG dataset for improving MLLM SVG generate performance. Check our Project Page and Hugging Face.
- 2025.06: We propose ReDit, a technique that enhances reinforcement learning in large language models by adding random perturbations to reward signals, improving training efficiency and convergence speed while maintaining performance. Check our Github.
- 2025.06: 🎉🎉 Flexora is accepted by ACL 2025.
- 2025.02: We propose PAFT, which dynamically adjusts prompts during training, improving robustness, generalization, and even inference speed. Check our Github.
- 2024.08: We propose Flexora, a novel method that enhances Large Language Model fine-tuning efficiency by selectively adapting only the most critical layers. Check our Github.
- 2024.02: We propose Data Interpreter, an LLM agent for solving data science problems. Check our Github.
📝 Publications
† Equal Contribution
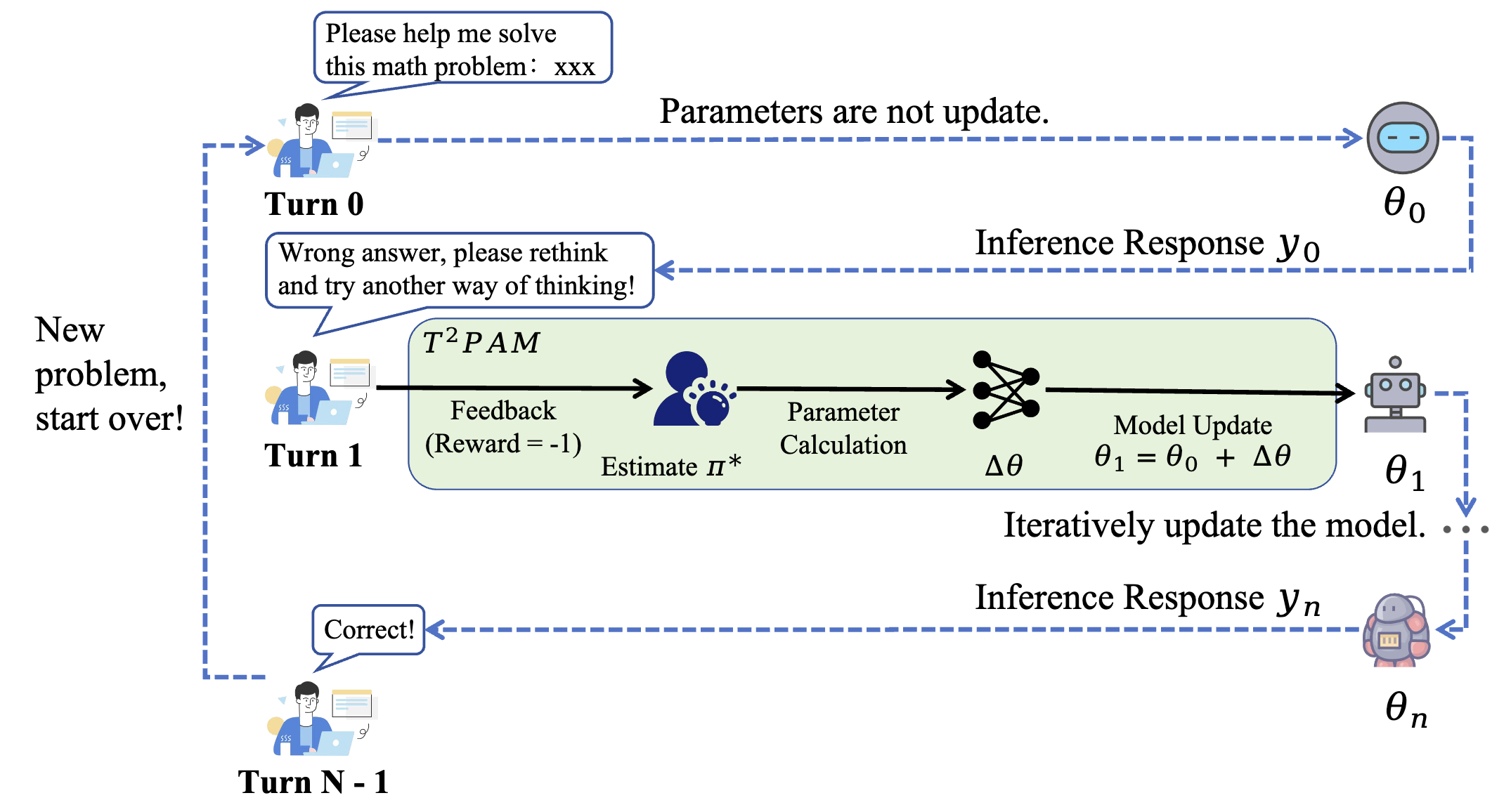
Test-Time Policy Adaptation for Enhanced Multi-Turn Interactions with LLMs
Chenxing Wei, Hong Wang, Ying He, Yao Shu, Fei Yu
- Paradigm (T2PAM): Proposes a paradigm shifting alignment from offline training to test-time inference, utilizing conversational feedback for real-time policy updates
- Algorithm (ROSA): Introduces ROSA, a lightweight algorithm that performs single-step, analytical parameter updates for efficient in-conversation self-correction
- Theory: Proves monotonic error reduction at each turn and guarantees cumulative convergence to the user’s optimal preference
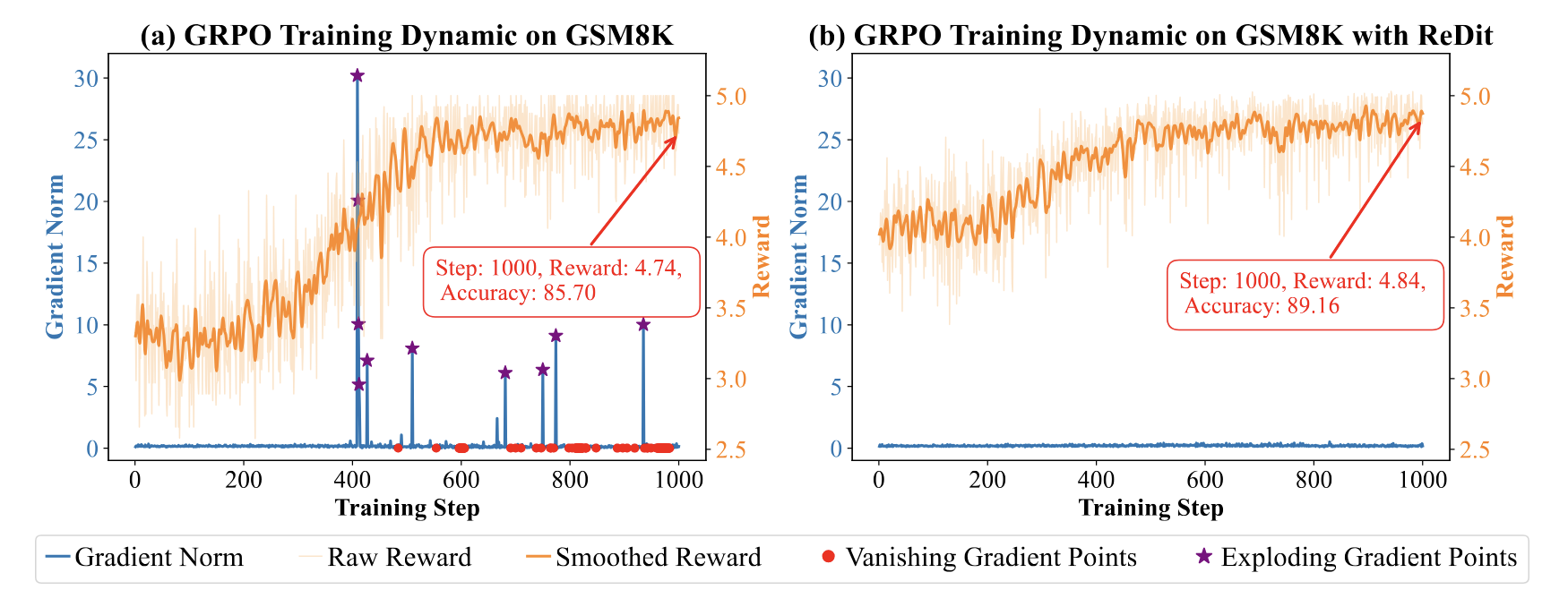
ReDit: Reward Dithering for Improved LLM Policy Optimization
Chenxing Wei, Jiarui Yu, Ying Tiffany He, Hande Dong, Yao Shu, Fei Yu
Paper | OpenReview | GitHub
- Algorithm (ReDit): a method that injects zero-mean random noise into rewards to smoothen the landscape, enabling continuous and stable gradient estimation.
- Theory: proves that reward dithering effectively mitigates gradient anomalies (vanishing/exploding) and significantly accelerates convergence.
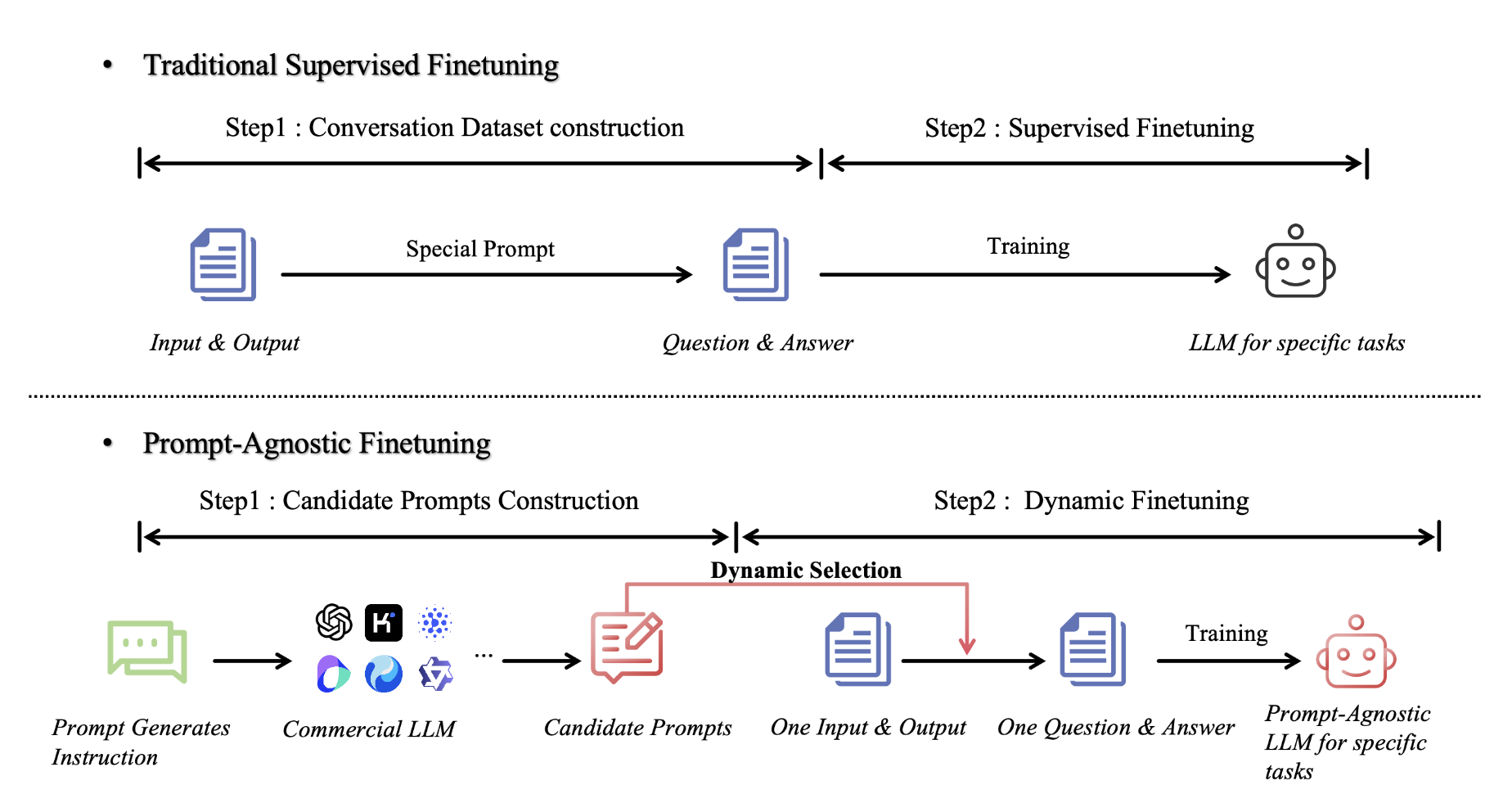
PAFT: Prompt-Agnostic Fine-Tuning
Chenxing Wei, Yao Shu, Mingwen Ou, Ying Tiffany He, Fei Richard Yu
- Algorithm (PAFT): Introduces PAFT, which minimizes the divergence between predictions from full prompts and “pattern-free” inputs, effectively decoupling task reasoning from specific instruction syntax.
- Theory: Theoretically guarantees reduced generalization error under prompt distribution shifts and empirically achieves state-of-the-art robustness.
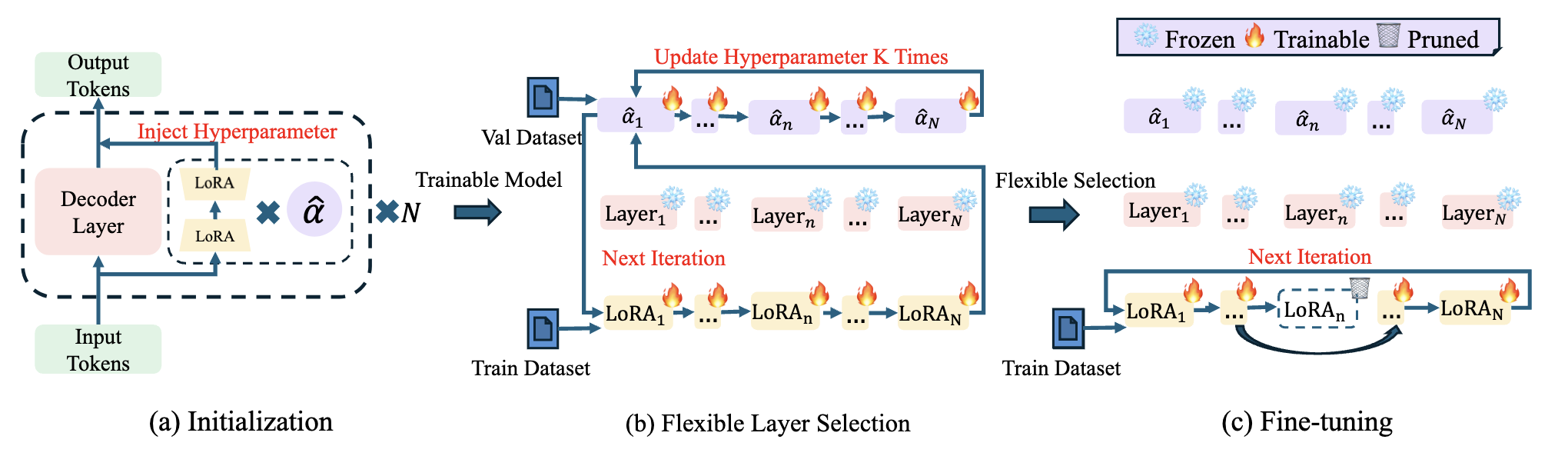
Flexora: Flexible Low-Rank Adaptation for Large Language Models
Chenxing Wei†, Yao Shu†, Ying Tiffany He, Fei Yu
- Algorithm (Flexora): Introduces Flexora, a framework that treats layer selection as a Hyperparameter Optimization (HPO) problem. It employs unrolled differentiation to automatically learn a policy that identifies and adapts only the most critical layers for specific downstream tasks.
- Theory: Provides theoretical insights into how automated, flexible layer selection effectively mitigates overfitting and enhances generalization compared to uniform adaptation.
🎡 Service
- Reviewer for ICLR’2026
🎖 Honors and Awards
- 2025.11 Senior Area Chair Highlights Award of EMNLP 2025.
- 2025.10 National Scholarship Shenzhen University
- 2025.09 First-Class Academic Scholarship Shenzhen University
- 2023.09 Second-Class Academic Scholarship Shenzhen University
- 2022.06 First Prize in the TI Cup National Undergraduate Electronics Design Contest Nanjing University of Aeronautics and Astronautics
- 2021.06 First Prize in the Contemporary Undergraduate Mathematical Contest in Modeling Nanjing University of Aeronautics and Astronautics
📖 Educations
-
Shenzhen University

Master, Computer Science, 2023.09 - (now),
Advisor: Prof. Fei Richard Yu, Co-Advisor: Prof. Yao Shu
-
Nanjing University of Aeronautics and Astronautics

Undergraduate, 2019.09 - 2023.06,
Advisor: Prof. Hanlin Sheng
💻 Internships
-
ByteDance

Algorithm Intern, MarsCode Trae Team, 2025.10 - (now),
Main contributions: Research on reinforcement learning for diffusion language models in code modification
-
Tencent

Algorithm Intern, CSIG CodeBuddy Team, 2025.02 - 2025.09,
Main contributions: Research on self-play reinforcement learning framework for GUI agents.
-
Tencent
Algorithm Intern, AI LAB Digital Human Team, 2024.06 - 2024.12,
Main contributions: Research on emotion and action prediction model of the game NPC and Scaling Law.
👾 Misc
